
Le DLL sono librerie di funzioni, che necessitano di altri programmi per essere eseguite. Chiunque è in grado di costruirsi la propria libreria di funzioni, semplicemente con la conoscenza del linguaggio C o C++ e un compilatore. Fra questi ce ne sono in particolare due molto usati e gratuiti: Bloodshed DevC++ con licenza GNU e Microsoft Visual C++ Express che pure è un ambiente di sviluppo gratuito con limitazioni più che altro nei wizard e negli strumenti di aiuto.
Normalmente, se costruiamo una DLL e questa viene utilizzata da diverse applicazioni ogni processo che carica quella DLL avrà la sua copia delle variabili, anche fossero dichiarate come globali. Questo è un comportamento del tutto logico e consente di dare stabilità e sicurezza al sistema.
Potrebbe tuttavia esserci la necessità di condividere dati fra processi diversi, in questo caso esiste un modo di dichiarare una variabile in una sezione di memoria condivisa.
Vediamo come condividere una variabile che chiameremo banalmente sharedint, appunto di tipo int, utilizzando la sintassi adatta in modo specifico al compilatore Visual C++, vedremo in seguito come ottenere lo stesso risultato utilizzando il compilatore Bloodshed DevC++ (che si appoggia a gcc).
Per prima cosa, dobbiamo fornire al pre-processore le seguenti direttive pragma:
1 2 3 4 5 | #pragma data_seg("SHARED") // Begin the shared data segment. // Define variable int sharedint = 0; #pragma data_seg() // End the shared data segment #pragma comment(linker, "/section:SHARED,RWS") |
Quindi definiamo la funzione DllMain che deve essere sempre presente in qualsiasi DLL. In realtà, quando scegliamo un progetto di tipo DLL sarà l’IDE stesso a scrivere questo per noi!
Notate che la funzione è preceduta da due modificatori: il primo: BOOL non è altro che un typedef ad un int ed è definito nell’header windows.h il secondo: APIENTRY, più interessante, è un typedef a WINAPI che è a sua volta un typedef a _stdcall. Si tratta di una calling convention che impone alla funzione chiamata di ripulire lo stack, compito che di default ( _cdecl ) viene invece eseguito dal chiamante. Se utilizzeremo la nostra DLL in Visual Basic, è richiesto l’utilizzo di _stdcall.
Infine definiamo due funzioni, che saranno quelle esportate dalla DLL:
SetNumber(int num1)che prende come input un intero e lo memorizza nella variabile definita nell’area di memoria condivisaGetNumber()che restituisce l’intero impostato nella variabile definita nell’area di memoria condivisa
Ecco il codice completo per Visual C++:
// dllmain.cpp: definisce il punto di ingresso per l'applicazione DLL. #include "stdafx.h" #pragma data_seg("SHARED") // Begin the shared data segment. // Define variable int sharedint = 0; #pragma data_seg() // End the shared data segment #pragma comment(linker, "/section:SHARED,RWS") BOOL APIENTRY DllMain( HMODULE hModule, DWORD ul_reason_for_call, LPVOID lpReserved ) { switch (ul_reason_for_call) { case DLL_PROCESS_ATTACH: case DLL_THREAD_ATTACH: case DLL_THREAD_DETACH: case DLL_PROCESS_DETACH: break; } return TRUE; } int __stdcall SetNumber(int num1) { sharedint = num1; return TRUE; } int __stdcall GetNumber () { return sharedint; } |
Ci siamo quasi, ma prima di compilare dovremo informare il linker quali sono le funzioni che vogliamo esportare. Questo avviene preparando un file di definizioni (.def) in questo modo:
LIBRARY shareIntVc.dll EXPORTS SetNumber GetNumber
Impostiamo il riferimento al file DEF nella finestra delle proprietà del progetto come nella figura qui sotto:
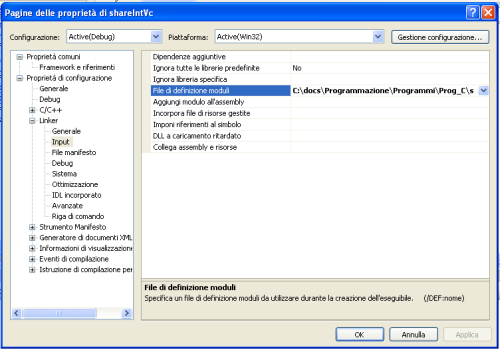
Compiliamo ed il gioco è fatto! Se non abbiamo avuto errori dal compilatore, troveremo la DLL nella sottocartella del progetto: debug.
Il progetto per Visual C++ 2008 lo potete prelevare qui.
Per testare la DLL potete prelevare questo progetto in Visual Basic 6, avendo cura di modificare il file module1.bas (che contiene le dichiarazioni delle funzioni importate), indicando il percorso corretto della DLL sul vostro PC e ricompilando il sorgente. Lanciando più istanze dell’eseguibile Visual Basic sarà possibile leggere da ogni istanza la variabile impostata.
Vediamo infine come cambia il codice della nostra DLL utilizzando il compilatore Bloodshed DevC++: l’unica differenza sta nella sostituzione delle direttive pragma con: l’utilizzo dello specificatore di attributi delle variabili : __attribute__((section ("shared"), shared))
Ecco il codice completo per Bloodshed DevC++:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | #include #include #include int sharedint __attribute__((section ("shared"), shared)) = 0; BOOL APIENTRY DllMain (HINSTANCE hInst /* Library instance handle. */ , DWORD reason /* Reason this function is being called. */ , LPVOID reserved /* Not used. */ ) { switch (reason) { case DLL_PROCESS_ATTACH: break; case DLL_PROCESS_DETACH: break; case DLL_THREAD_ATTACH: break; case DLL_THREAD_DETACH: break; } /* Returns TRUE on success, FALSE on failure */ return TRUE; } int _stdcall SetNumber(int num1) { sharedint = num1; return TRUE; } int _stdcall GetNumber() { return sharedint; } |
Anche qui è necessario definire le funzioni esportate in un file di definizioni che sarà identico a quello utilizzato con Visual C++, e impostarlo nella sezione “Opzioni del progetto” -> “Parametri” -> “Linker”, come mostrato nella figura qui sotto:
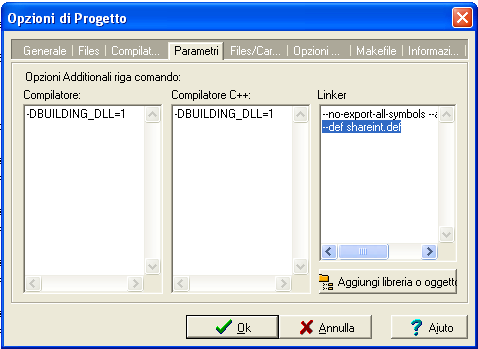
Il progetto per Bloodshed DevC++ lo potete prelevare qui.
Conclusioni:
L’utilizzo della memoria condivisa con le DLL si rivela utile per scambiare dati fra diverse applicazioni, ma bisogna fare attenzione alle potenziali violazioni della memoria. Per ottenere un funzionamento sicuro, sarebbe necessario implementare un sistema di sicronizzazione dell’accesso ai dati condivisi attraverso un mutex o una critical section.
Riferimenti ed approfondimenti:
- Can you share global variables between a DLL and a calling program?
- Sharing Variables Between Win32 Executables
- Step by Step: Calling C++ DLLs from VC++ and VB
- Dev-C++ and DLLs question
- Using the GNU Compiler Collection: Specifying Attributes of Variables
- Stdcall and DLL tools of MSVC and MinGW
- Hooks and DLLs
luciano ha scritto:
si ok l’ho provata e funziona perfettamente ..
mi chiedo se anziche un int volessi una una variabile stringa
come diventerebbela dll ?
ciao Luciano
02.11.10 18:50
Mario Spada ha scritto:
@Luciano: Con le stringhe il discorso si complica un poco perché il C tratta le stringhe come byte array terminate da un NULL char, mentre VB usa BSTR che sono stringhe unicode. Ad ogni modo la cosa è fattibile, e nemmeno troppo complicata. Purtroppo in questo momento non ho tempo di preparare un esempio, ma ti posso suggerire questi due link molto esaurienti:
1) http://sandsprite.com/CodeStuff/Writing_A_C_Dll_for_VB.html
2) http://support.microsoft.com/kb/187912
08.11.10 19:20



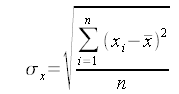
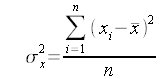

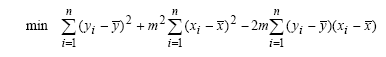
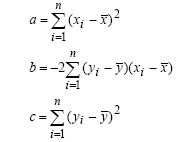
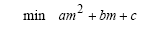
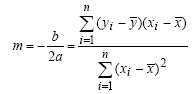

 Questo è un piccolo esercizio per imparare ad utilizzare le funzioni per disegnare con le lbrerie
Questo è un piccolo esercizio per imparare ad utilizzare le funzioni per disegnare con le lbrerie